私はPayPayの社員ではないが、ただ自己趣味でこの記事は英語から翻訳したのです。日本語を勉強中ですから、この記事には間違いが多いかもしれません。もし文法や言葉を間違えていたら、教えてくれるとありがたいと思います。
英語の元記事をご自由にご覧になってください。
PayPayとは、モバイル決済サービスを提供するアプリケーションです。日本はまだ現金主義社会ですが、大規模なキャンペーンとキャッシュレス社会に向けた政策支援で、PayPayが急速に発展しています。現在、日本国内には約3000万人のユーザーと200万の加盟店が利用し、最近の取引量も10億に達していました。
去年、PayPayの事業が急成長した際、決済トランザクションを管理する最もミッションクリティカルなデータベースであるPaymentデータベースは、書き込み負荷が大きく、ボトルネックになっていました。慎重に調査した後、我々はAmazon AuroraからオープンソースのHTAP分散型データベースであるTiDBに移行することにしました。TiDBが水平方向にスケール可能のおかげで、データベースの容量を心配する必要がなくなりました。
本記事は、PayPayがAuroraからTiDBに移行した理由及びその移行の経過について説明します。
限られていたデータベース容量
PayPayはオンラインとオフラインの支払いに対応しており、複数の支払い方法を提供します。我々がインフラストラクチャとしてAWSを使用し、その上でマイクロサービスアーキテクチャを構築しています。
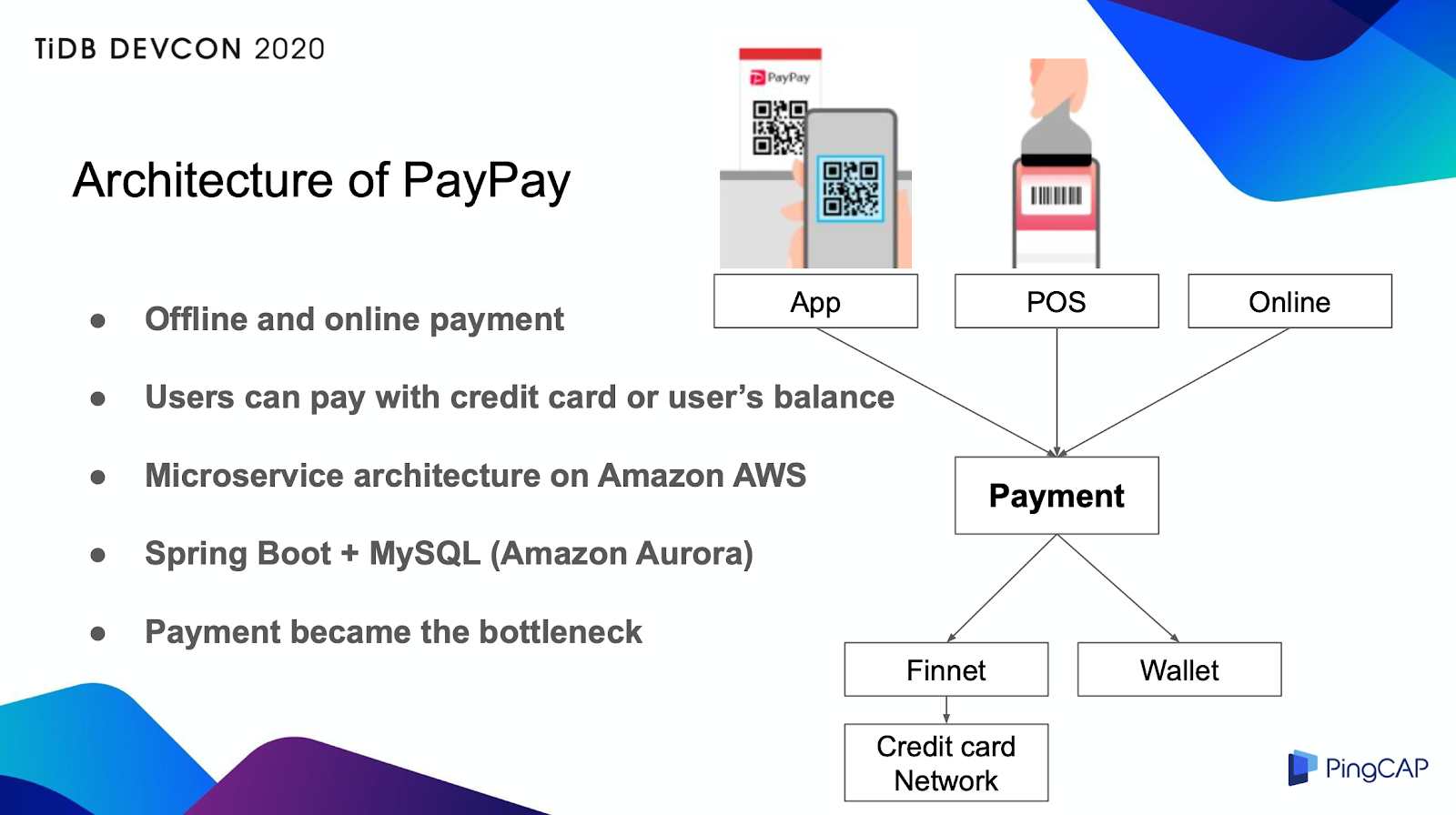
PayPayのアーキテクチャ
コンポーネントが約80個あり、ほとんどがデータベースアーキテクチャとしてJava、Spring Boot、Auroraを使用しています。そして、全ての支払いトランザクションは、管理のためにPaymentコンポーネントに送信されます。
決済トランザクションが発生すると、データがPaymentデータベースに書き込まれたが、それでトランザクションの状態も更新されます。そのため、Paymentデータベースは書き込みの多い負荷があります。業務量の増加と相まって、当時はPaymentデータベースがボトルネックになっていました。このように、よりスケールアウトできるデータベースに移行することにしました。
TiDBを選ぶ理由は?
TiDBは、PingCAPとそのオープンソースコミュニティによって構築されたオープンソース、クラウドネイティブ、分散型SQLデータベースです。新しいデータベースとしてTiDBを選ぶ理由はいくつかあります。
- TiDBがMySQLとの互換性があり、アプリケーションコードの変更はほとんどありません。しかしながら、分散型DBのせいで、IDのオートインクリメント(auto-increment)に注意点がありますが、このような変更は少ないです。
- 水平方向にスケール可能で、将来のデータの増加にも簡単に対応できます。さらに、TiDBのクラスタは複数のインスタンスで構成されており、高可用性を保ちます。PayPayのクラウドネイティブアーキテクチャも、TiDBにはよく合っています。
- 開発者がアプリケーションでシャーディング(sharding)をする必要がないので、アプリケーションをシンプルにすることができます。データベースがボトルネックになると、通常はユーザーIDをシャーディングキーにしてシャディングを行い、複数のデータベースにデータを分けて保存します。そうは言っても、この方法ではアプリケーションがシャディングロジックを処理する必要があり、複雑になります。しかし、TiDBを使用すれば、この問題はなくなります。
- 多くの企業がすでに本番環境でTiDBを使用しています。TiDBには、様々な会社で、特に金融分野での豊富な経験がありますので、我々はこの新技術に対する信頼できます。意思決定者にとってはこれが最も説得力のある点です。
TiDBと比較して、Auroraには2つのメリットがあることが分かりました。
- Auroraは、デフォルトで1つの書き込み専用のプライマリエンドポイントと1つの読み取り専用のセカンダリエンドポイントを使用します。エンドポイントの間のレプリケーションのレイテンシは非常に小さいです。例えば、セカンダリで遅いクエリが発生した場合、プライマリの書き込みパフォーマンスには影響を与えません。二つのエンドポイントを適当に使用すれば、安定性を確保できます。
- AuroraはAWSによって管理されたサービスなので、コストが安いです。
しかし、Auroraが多くの書き込みリクエストを処理する時、binlogレプリケーションがボトルネックになります。コミットプロセスの間、Auroraはレプリケーション先が確認応答(ACK)を待つので、レプリケーションの数が増えたっら、コミットの待ち時間も増えます。ディザスタリカバリのためには、レプリケーションが必要だったので、この問題は深刻化する一方だった。
TiDBはAuroraと違う。TiDBの概念実証(POC)を行った際、このような問題は全然発生しませんでした。TiDBは、Auroraの3倍以上のトランザクションを楽に対応できます。公平に言うと、Auroraが優れたデータベースです。我々はAuroraからTiDBに移行にしたのは、binlogレプリケーションのみのわけではありません。
様々な原因を総合して、TiDBへの移行するのを決定した。
TiDBを使っているPaymentデータベース
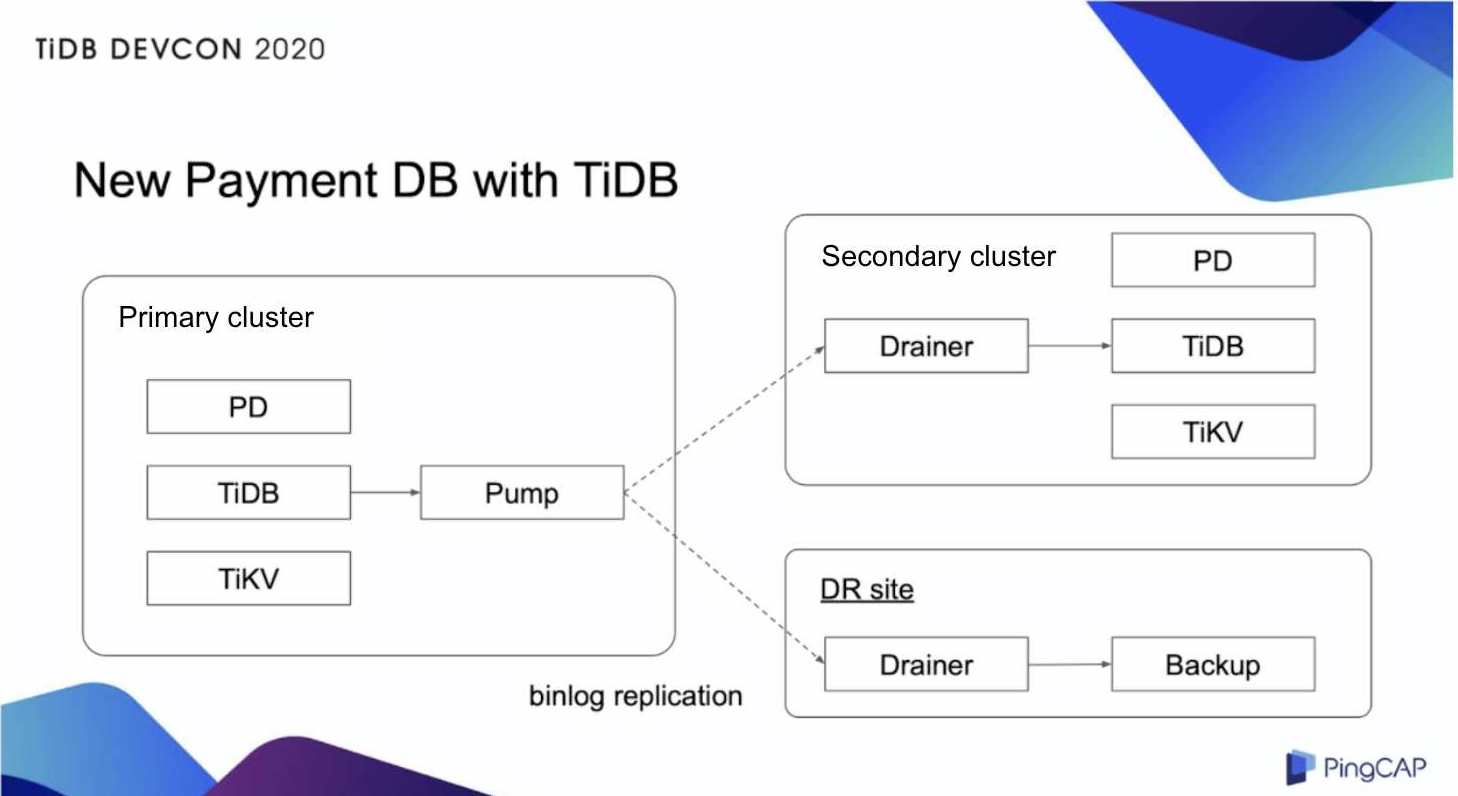
TiDBを使っているPaymentデータベース
TiDBクラスタには、TiDB、TiKV、PDという三つのコンポーネントがあり、各コンポーネントが複数のインスタンスを持っている。また、Pump、Drainerと呼ばれるコンポーネントを使い、binlogをセカンダリクラスタとディザスタリカバリのサイトにレプリケートする。複数のインスタンスは別々のデータセンターに配置されている。この仕組みのおかげて、このクラスタはフォールトトレラント性が高くなっている。
移行の実践経験
すると、TiDBに移行するかどうかの検討にはほぼ1ヶ月をかかりました。その後、2ヶ月で詳細な検証を行いました。
データの完全性テスト
最初のテストはデータの完全性です。我が社のアプリケーションとの連続後、TiDBが期待通りに働くことを確認していたが、これを確実にするため、インドメイン(in-domain)検証とクロスドメイン(cross-domain)検証の2種類の検証を導入しました。
in-domain検証
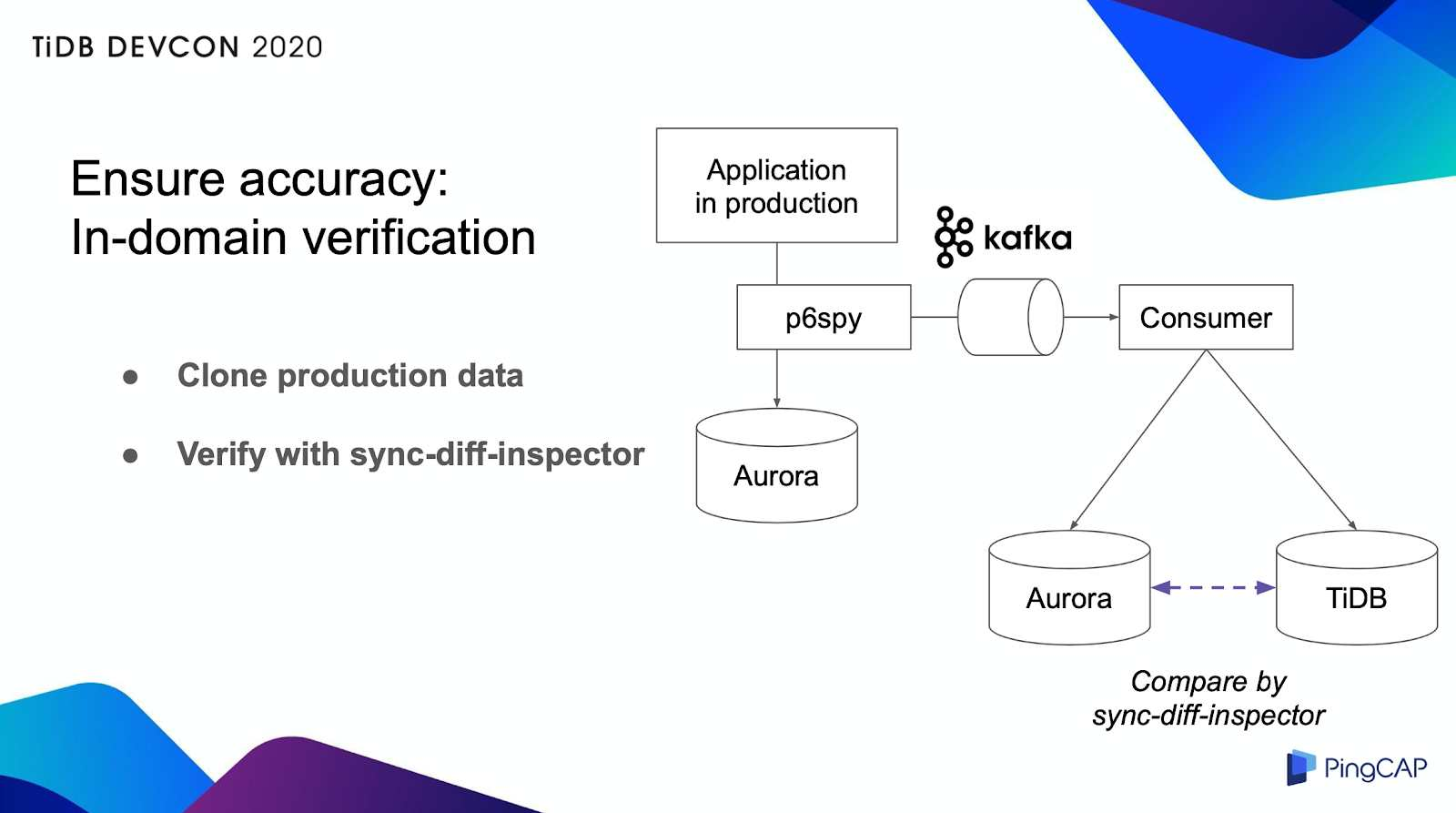
in-domain検証
もちろん、このテストはテスト環境で行ったのです。しかし、実際の本番データでテストをしてTiDBの動作を確認したかったから、本番トラフィックを別のAuroraとTiDBにクローンして、データが全く同じかどうかを確認しました。そのため、p6spyというフレームワークを使いました。
P6spyはJDBC接続で送信されたデータをキャプチャし、そのデータをKafkaメッセージキューに送信する。アプリケーションはKafkaからデータを受信し、データベース操作をAuroraとTiDB上で実行する。その後、TiDBが提供したsync-diff-inspectorを用いて、AuroraとTiDBのデータセットを比較した。結局、AuroraとTiDBのデータは全く同じであることを確認した。
このテスト方法は、本番データベースに負荷をかけることなくテストを完了できるという利点がある。
cross-domain検証
私たちのシステムはマイクロサービスアーキテクチャを使用しているので、Paymentデータベースと他の隣接コンポーネントとの間に整合性チェックも行ました。下図のように、Hadoopに似ていたアーキテクチャであるAmazon Elastic MapReduce (EMR)を使用しました。
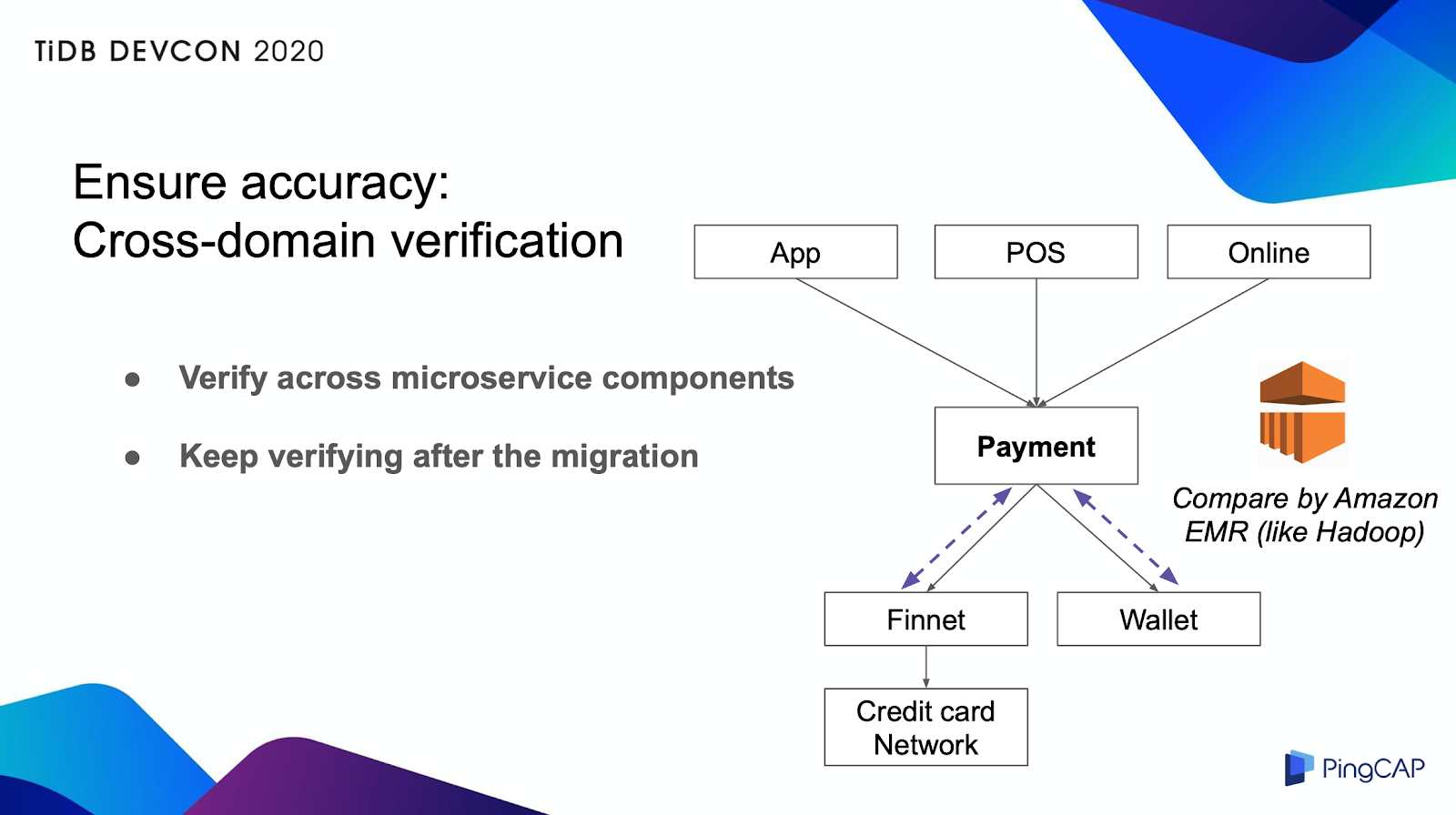
cross-domain検証
数分ごとに、各データベースからデータを取り出し、EMRに渡し、この期間各のコンポーネントの整合性を継続的にチェックしていました。このチェックは移行前も移行後も実施されていたということは、移行後も未知の問題を発見できるシステムであってほしいのためです。
性能と可用性テスト
Auroraでは扱えないような高いTPS(1秒当たりのトランザクション処理件数)を処理する能力はすでにもっているので、パフォーマンスを向上させるためにアプリケーションをチューニングしました。例えば、接続プールのサイズを増やし、不要なインデックスを削除しました。TiDBはAuroraの3倍のTPSを1秒以下の決済レイテンシで上手く処理できる。
障害ケーステストにかかっては、我が社はインスタンス障害、クラスタ障害、AZ障害など30以上のシナリオをシミュレーションしました。その中、目標復旧時点(RPO)、目標復旧時間(RTO)などの指標を確認しました。BinlogレプリケーションのおかげでRPOをほぼゼロに近づけることができましたが、大量のデータの関係でRTOが高くなっています。今後、大規模な障害が発生しないようにするためには、復旧時間を短縮する必要がある。
移行の経過
移行中のリスクを減らすために、インクリメンタルな方法で徐々にトラフィックを増やしていくことも検討したが、実装は難しかった。読み込み専用のデータベースであれば、トラフィックを制御するのは簡単ですが、書き込み専用のデータベースでは、実装は非常に複雑になる。そこで、単発的なアプローチを選択した。
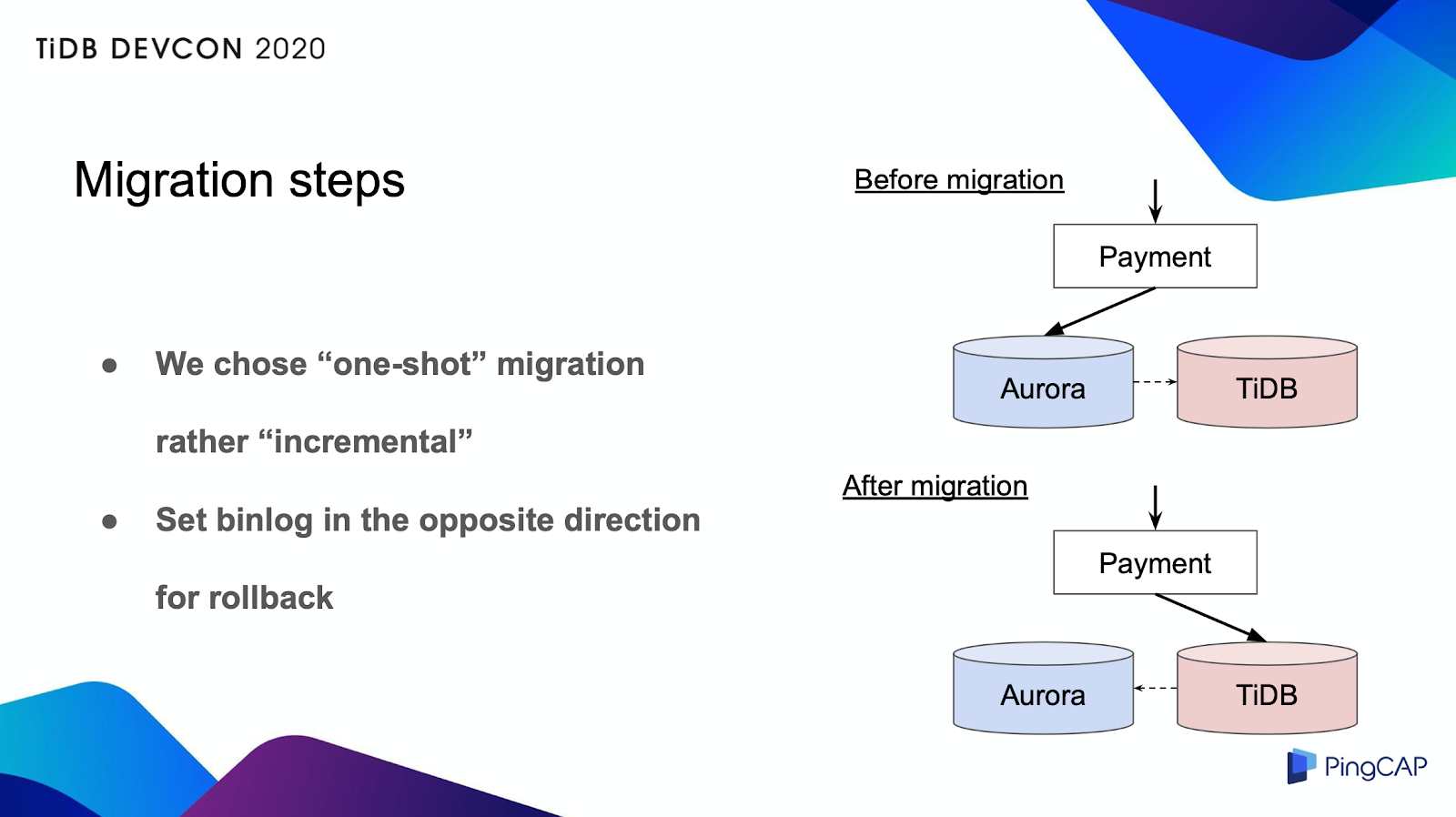
移行の経過
この単発的な移行方法はシンプルですが、何かあった場合、全てのユーザーに影響が出るのリスクが高いです。そのため、いざとなればすぐにロールバックできることが重要です。最初データ移行時にはbinlogレプリケーションを行っていたが、移行作業中にレプリケーションを逆方向に設定しました。これで、何かあってもすぐにロールバックできるように、Auroraをバックアップとして利用しています。
同様に、移行前に社内で何度もリハーサルを行っていた。実際の移行は、検証時間を含めて約2時間で問題なく完了し、サービスのダウンタイムも最小限に抑えることができました。
移行して3ヶ月になりましたが、TiDBは期待通りのパフォーマンスを発揮しています。この3ヶ月間、インシデントは発生していません。TiDBはすばらしくて、非常に信頼性が高いです。さらに、PingCAPのサポートにも感謝したいと思います。我が社はPingCAPから多くの助けをもらって、彼らとTiDBを信頼するようになりました。この場を借りて、改めて感謝の意を表したいと思います。
今後の計画
現在、我が社がTiDB 2.x バージョンを使用している。これは、我が社のデータベースがミッションクリティカルであり、2.x バージョンは成熟したリリースであるからです。今年後半には3.x以上にアップグレードする予定です。TiKV Regionsの効率的な利用やバックアップ機能の向上など、多くのメリットが期待しています。また、必要に応じて、Payment以外のデータベースもTiDBに移行したいと考えています。
最後に、私たちの知識や経験をTiDBコミュニティと共有したいと思います。今後、TiDBがよりデータベースになっていくことを心から願っています。