这周收到了室友的求助,问我能不能把几千个病人的检测报告信息从 Word 里提取到 Excel 里,他们医院论文要分析数据。
查了下感觉可以用 python-docx 从 docx 提取数据,再用 pandas 写入到 Excel 里,听起来不难,下班就开干。
分析原始文件
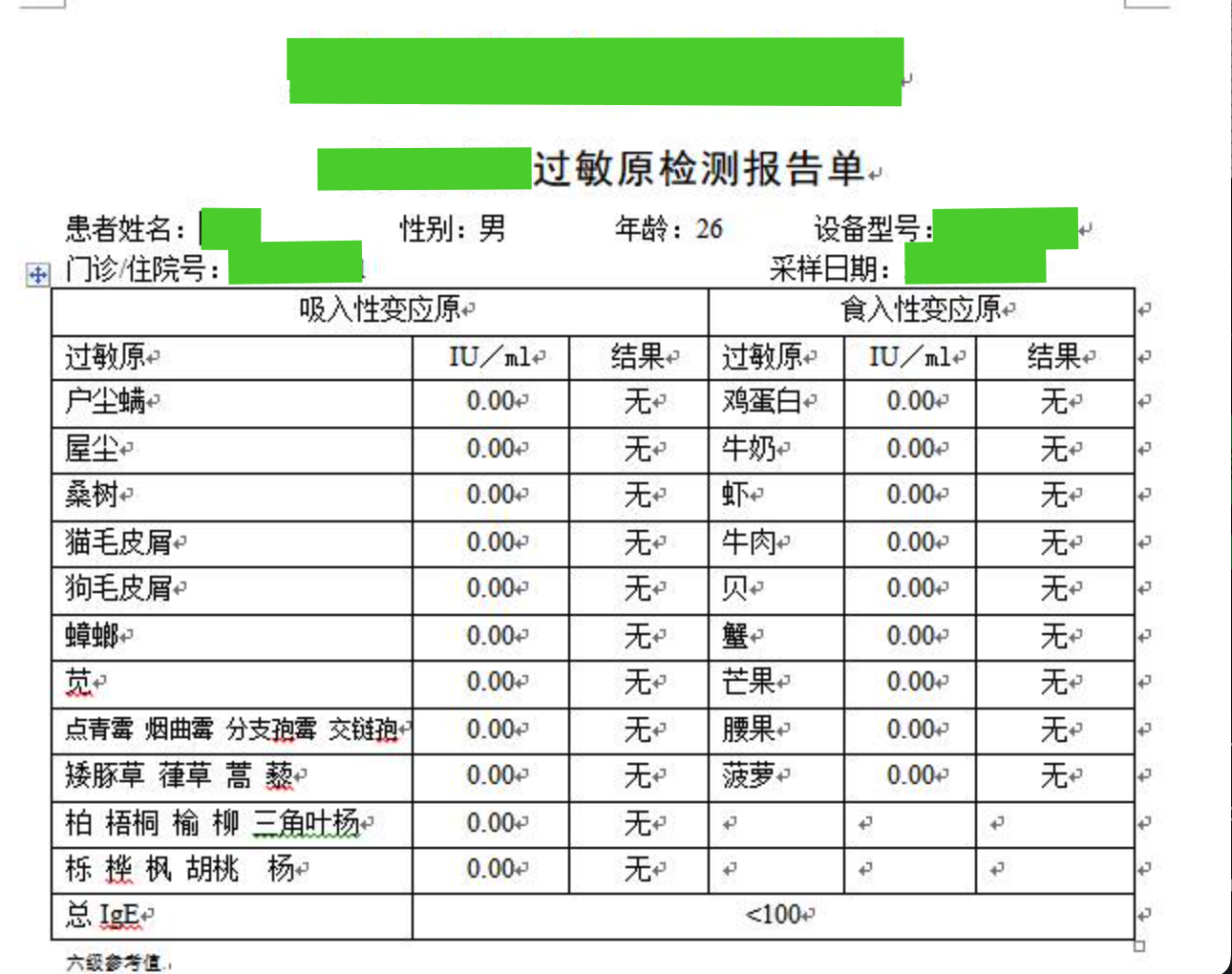
先来分析下我需要的数据。
- 姓名、性别、年龄、设备型号在第一行,以空格和冒号分割。
- 门诊住院号和采样日期在第二行,以空格和冒号分割。
- 过敏原和检测数据在表格里,分为左右两个半区。
读取 docx 数据
第一次用 python-docx 库,还好这个库的接口很简单。生成一个 Document 对象后,就可以用 .paragraphs 返回一个包含所有段落的列表:
1 | import docx |
这样就能把一个段落提取出来:
1 | 患者姓名:张三 性别:女 年龄:28 设备型号:xxxxxx |
再结合 .split() ,把对应字段的值提取出来。病人信息就搞定了。
读表格单元格也非常简单,指定行列数即可:
1 | my_tbl = document.tables[0] |
检测数据也就拿到了。再套个循环,把目录下的文件都读一遍。Done.
错误处理
由于每一份原始文件都是医院人员手打的,可能存在一些格式不标准的情况,所以又在循环外面加了 try-except,如果有报错,单独打印到一个文件里,不影响其他文件的读取。
如果遇到不是 .docx 格式的文件,也需要单独打印出来,然后跳过。
输出到 Excel
接下来就考虑怎么写入 Excel。虽然知道可以用 pandas,但我看了一眼文档,感觉 3 分钟内搞不定,算了,不费这劲。
想了想可以把每个病人的字段拼接成一个 string,打印到一个 txt 里:
1 | 张三 女 28 xxxxxx K178XXX 2019-9-XX 0.00 0.00 0.00 0.00 5.0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 <100 |
再贴到 Google Sheets,用 split data into columns,完事!
转换 doc 为 docx
完成了最核心部分的逻辑,摆在我们面前的还有一个难题:怎么把 .doc 批量转换成 .docx。
医院的上古操作系统里只有 .doc,但 python-docx 只支持 .docx。
遇事不决,StackOverflow。果然搜到了用 soffice 来批量处理的办法。不愧是 soffice,轻易就做到了 Word 做不到的事。
1 | # 批量转换 .doc 文件为 .docx,并输出到 converted_docx 目录下 |
但这个转换方式有点慢,每个文件需要三四秒。电脑还在跑,我就去睡了。但 Mac 本来也是留在家里做网关的,所以也无所谓了,就是风扇声真的很大。Intel しね!
意外
把上面的几步拼装起来,我就得到了一个可以沃克的脚本。
结果还是出了点意外,最终成品的 Excel 如下,采样日期一栏有一些奇怪的数据。
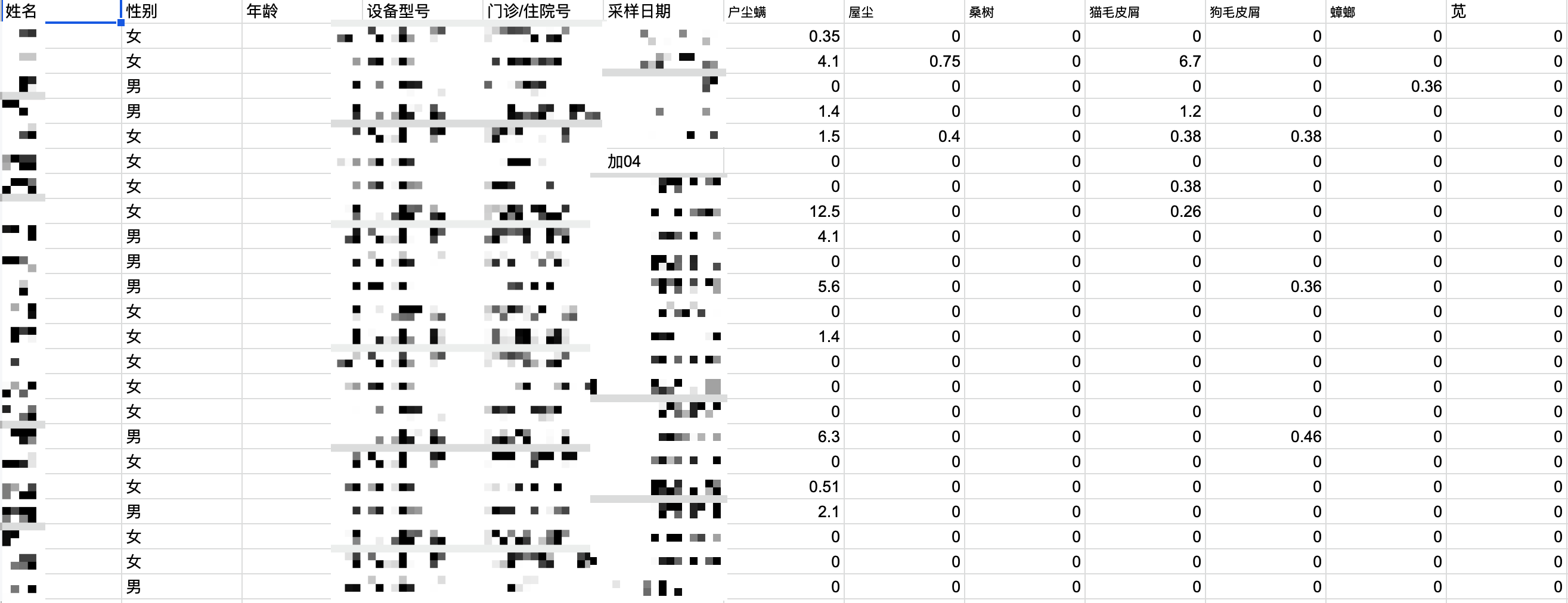
查了下对应的源文件,发现是因为有一小部分病人是住院的,所以门诊/住院号和采样日期之间,多了一个字段:住院床位。

要处理这个也很快,过滤出这一部分异常数据,再多读一个字段就行了。但原始数据竟然不标准,我也不知道说啥好了。
总结
完成这个小脚本,从调研到写代码,再到测试,总计花了大约 3 小时。学到了:
- python-docx,用过都说好!
- 错误处理,比我想的简单。
- soffice,很强大。
室友十分感动,说要跟导师申请,论文给我署名。我即将拥有人生第一篇北大核心?
我:还是周末帮我洗下空调比较实际。